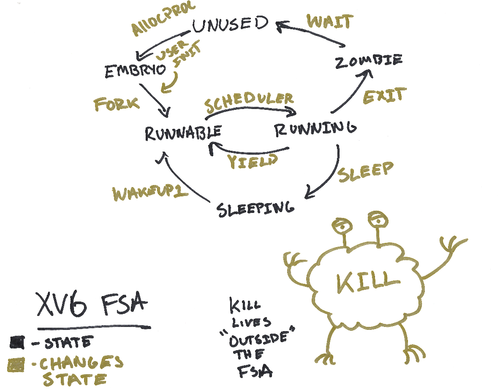
// Per-process state structproc { structspinlocklock;
// p->lock must be held when using these: enumprocstatestate;// Process state void *chan; // If non-zero, sleeping on chan int killed; // If non-zero, have been killed int xstate; // Exit status to be returned to parent's wait int pid; // Process ID
// wait_lock must be held when using this: structproc *parent;// Parent process
// these are private to the process, so p->lock need not be held. uint64 kstack; // Virtual address of kernel stack uint64 sz; // Size of process memory (bytes) pagetable_t pagetable; // User page table structtrapframe *trapframe;// data page for trampoline.S structcontextcontext;// swtch() here to run process structfile *ofile[NOFILE];// Open files structinode *cwd;// Current directory char name[16]; // Process name (debugging) };
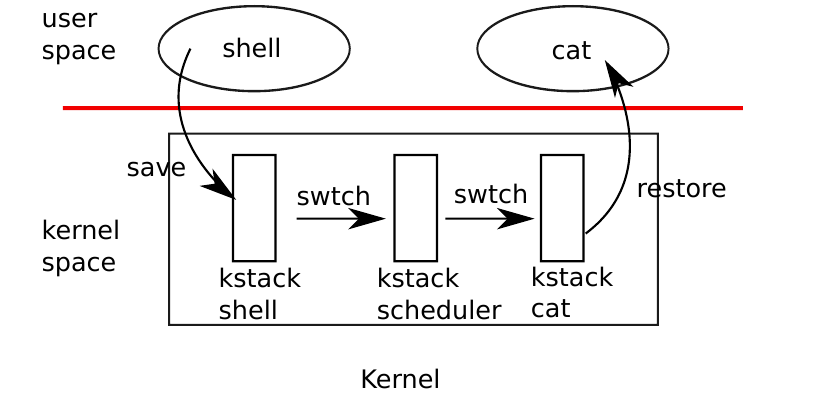
void scheduler(void) { structproc *p; structcpu *c = mycpu(); c->proc = 0; for(;;){ // Avoid deadlock by ensuring that devices can interrupt. intr_on();
for(p = proc; p < &proc[NPROC]; p++) { acquire(&p->lock); if(p->state == RUNNABLE) { // Switch to chosen process. It is the process's job // to release its lock and then reacquire it // before jumping back to us. p->state = RUNNING; c->proc = p; swtch(&c->context, &p->context); // 保存context(上下文)
// Process is done running for now. // It should have changed its p->state before coming back. c->proc = 0; } release(&p->lock); } } }
// Give up the CPU for one scheduling round. void yield(void) { structproc *p = myproc(); acquire(&p->lock); // 这里也要加一个自旋锁,如果不加,在yield过程中来一个中断之类的会出问题 p->state = RUNNABLE; sched(); // 这里调用sched切换进程(恢复上下文等操作) release(&p->lock); }
yield 调用了 sched
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
void sched(void) { int intena; structproc *p = myproc();
// Per-CPU state. structcpu { structproc *proc;// The process running on this cpu, or null. structcontextcontext;// swtch() here to enter scheduler(). int noff; // Depth of push_off() nesting. int intena; // Were interrupts enabled before push_off()? };
// Atomically release lock and sleep on chan. // Reacquires lock when awakened. void sleep(void *chan, struct spinlock *lk) { structproc *p = myproc(); // Must acquire p->lock in order to // change p->state and then call sched. // Once we hold p->lock, we can be // guaranteed that we won't miss any wakeup // (wakeup locks p->lock), // so it's okay to release lk.
acquire(&p->lock); //DOC: sleeplock1 release(lk);
// Go to sleep. p->chan = chan; p->state = SLEEPING;
sched();
// Tidy up. p->chan = 0;
// Reacquire original lock. release(&p->lock); acquire(lk); }
staticvoidput(int key, int value) { int i = key % NBUCKET;
// is the key already present? structentry *e =0; for (e = table[i]; e != 0; e = e->next) { if (e->key == key) break; } if (e) { // update the existing key. e->value = value; } else { // the new is new. pthread_mutex_lock(&lock[i]); insert(key, value, &table[i], table[i]); pthread_mutex_lock(&lock[i]); } }
这个也是在Unix/linux真机下面,练习一下条件变量。这个barrier是用pthread_cond实现的,a point in an application at which all participating threads must wait until all other participating threads reach that point too.
staticvoidbarrier() { // Block until all threads have called barrier() and pthread_mutex_lock(&bstate.barrier_mutex); bstate.nthread++; if (bstate.nthread < nthread) { pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex); } pthread_mutex_unlock(&bstate.barrier_mutex);
staticvoidbarrier() { // Block until all threads have called barrier() and pthread_mutex_lock(&bstate.barrier_mutex); bstate.nthread++; if (bstate.nthread < nthread) { pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex); } if (bstate.nthread == nthread) { bstate.nthread = 0; bstate.round++; pthread_cond_broadcast(&bstate.barrier_cond); pthread_mutex_unlock(&bstate.barrier_mutex); } }
Go Map in Actions https://github.com/golang/go/blob/master/src/sync/map.go https://pkg.go.dev/sync?utm_source=godoc#Map Go 1.9 sync.Map揭秘 鸟窝大大写的sync.Mutex介绍
Operating Systems Three Easy Pices,中文就是那个蓝皮的操作系统导论 第29章,讲并发链表、并发队列和并发散列表 第20章,讲条件变量